Reinventing the Turing Test: Detecting Human vs AI Responses with Machine Learning
In the ever-expanding digital landscape, the challenge of distinguishing between genuine human responses and those generated by bots has become increasingly pertinent. Leveraging the power of Natural Language Processing (NLP) and classification modeling, this project attempts to tackle this challenge head-on by developing an AI system capable of accurately discerning between bot-generated and human-crafted responses. By harnessing data from Reddit discussions and interactions with ChatGPT, the project will meticulously train and test the AI model, exploring the nuances and patterns that distinguish between the two types of responses. Through this exploration, we aim to not only shed light on the efficacy of AI in tackling this pressing issue but also contribute to the development of more robust tools for maintaining the integrity of online conversations. Join us on this journey as we delve into the intersection of AI, NLP, and the intricacies of human communication.
Part 1 of this article focuses on Data Wrangling/Gathering/Acquisition. We will gather questions & answer pairs from various subreddits, then ask that same question too ChatGPT and gather that answer as well.
Part 2 focuses on Data Cleaning & EDA. We will clean our data, as well as perform elementary exploratory data analysis.
Part 3 focuses on NLP (Natural Language Processing) & Classification Modelling.
Below, I will include all the necessary imports needed for this project and a link to the github repo. Do note, all associated files can be found within the ‘medium’ folder.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import nltk
from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score
from sklearn.pipeline import Pipeline
from sklearn.naive_bayes import MultinomialNB, GaussianNB, BernoulliNB
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer, PorterStemmer
from nltk.tokenize import word_tokenizePart 1: Data Wrangling/Gathering/Acquisition
Initially, we need to gather data to which we can analyze. I decided to gather my human responses from Reddit, and my bot responses from ChatGPT.
Reddit Data Gather
Firstly, we need to set up the Reddit API. I suggest to check the docs below, but essentially you need to make an account so that you can have the necessary items to call and use the API (free to use).
https://praw.readthedocs.io/en/stable/getting_started/quick_start.html
import praw
import pandas as pd #Importing for use later
reddit = praw.Reddit(
client_id="",
client_secret="",
user_agent="dsi_project_3",
)Once filled in, we will need to collect various responses given a question. I chose subreddits predicated on posts which ask questions.
sr1 = reddit.subreddit('askculinary')
sr2 = reddit.subreddit('questions')
sr3 = reddit.subreddit('askengineers')
sr4 = reddit.subreddit('cscareerquestions')
sr5 = reddit.subreddit('askdocs')
sr10 = reddit.subreddit('TrueAskReddit')
subreddits = [sr1, sr2, sr3, sr4, sr5, sr6, sr7, sr8, sr9, sr10]Next, we will set up a function to gather said questions, and the top response for that question from a given subreddit. It will put this information in a dictionary, with the question and answer being the key-value pair respectively. Finally, we will add all of these key-value pairs into a list.
def question_and_answer(sr):
top_questions = sr.top(limit = 625) #Limit to collecting only 625 questions
q_and_a = []
for submission in top_questions:
if '?' in submission.title: #Only using posts with ? in it, to ensure questions are being used
top_comment = submission.comments[0].body if submission.comments else None
#Setting up dictionary
question_data = {
'title': submission.title,
'top_comment': top_comment
}
q_and_a.append(question_data) #Adding key-value pairs too listApply this function for each subreddit, turn the list into a dataframe, and combined all of these dataframes into one. You should then have a dataframe consisting of Reddit question & answers.
#Applying function too each subreddit
q_and_a_sr1 = question_and_answer(sr1)
q_and_a_sr2 = question_and_answer(sr2)
q_and_a_sr3 = question_and_answer(sr3)
q_and_a_sr4 = question_and_answer(sr4)
q_and_a_sr5 = question_and_answer(sr5)
q_and_a_sr10 = question_and_answer(sr10)
#Turning each list into a datafframe
df_sr1 = pd.DataFrame(q_and_a_sr1)
df_sr2 = pd.DataFrame(q_and_a_sr2)
df_sr3 = pd.DataFrame(q_and_a_sr3)
df_sr4 = pd.DataFrame(q_and_a_sr4)
df_sr5 = pd.DataFrame(q_and_a_sr5)
df_sr10 = pd.DataFrame(q_and_a_sr10)
#Combine all the dataframes above
df_reddit = pd.concat([df_sr1, df_sr2, df_sr3, df_sr4, df_sr5, df_sr10], axis = 0)Finally, we will export this into a csv file to be used later.
df_reddit.to_csv('reddit_ask_question.csv', index = False)ChatGPT Data Gather
For this part of the process, you will need to create an OpenAI account and gather an API Key which can be used to gather the necessary data. We will also read in our dataframe from the last step as they contain the questions which we will be asking ChatGPT.
import openai
import pandas as pd
openai.api_key = ''
reddit = pd.read_csv('df_reddit.csv')So one thing about OpenAI is they have various models which can be used to generate responses, each with it’s own pricing model. I will include the steps and model I used, although there are various ways to go about this to which you will incur various costs associated too using the API.
First step is to set up a function which uses ChatGPT to pose a question, and gather the response from that question.
def chat_with_gpt3(question):
response = openai.Completion.create(
engine = "text-davinci-003", #OpenAI Model
prompt = question, #Question to ask
temperature = 0.6, #Randomness within answer (sampling temp)
max_tokens = 500, #Adjust max_tokens based on the desired response length
n = 20 #Number of questions in a batch
)
#The below line was taken from docs to extract the response
return response['choices'][0]['text'] ##https://platform.openai.com/docs/guides/gpt/chat-completions-apiNext we will make a list of our questions taken from our dataframe, and run a loop to pose these questions to ChatGPT, and gather all of the responses in a separate list which we will call “answers”.
# Get the questions from the 'title' column of the dataframe
questions = reddit['title'].tolist()
# List to store the answers
answers = []
# Loop through the questions and get answers
for question in questions:
answer = chat_with_gpt3(question)
answers.append(answer)Once completed, we can now add these answers to our dataframe as our third column and export this dataframe into a csv file to be used later.
reddit['answers'] = answers
reddit.to_csv('reddit_ai_df.csv', index = False)At this point, your dataframe should look something like this with the appropriate headers for each column:

Do note, in my repo I had to break this part into steps as I continually got errors from the server side. I ended up breaking my questions into 8 parts, to which I applied the function to each part, got my lists of responses and combined them all to then be added as the final column too our dataframe.
Part 2: Data Cleaning & EDA
When it comes to cleaning the data, there is a lot to account for. Most of the cleaning has to do with automated messages by Reddit itself, or the way answers would come in when collected from ChatGPT. I tried too include all the ones I could find, which consists of:
- Need to remove rows which include [deleted] in comment
- Need to remove rows which include “#Message to all users…”
- Delete rows which have [removed]
- Remove rows which start with “Welcome”
- Remove NaN
- Remove various ways people use markdown shortcuts in Reddit comments
I will include a summarized version of the code I used to clean my data, for a more detailed version please visit the repo on GitHub.
#Read in csv file from previous part
real = pd.read_csv('reddit_ai_df.csv')
#Data Cleaning
real['answers'] = real['answers'].str.strip() #Removing white space from all ChatGPT answers
real = real.dropna() #Drop rows with NaN
real = real[real.top_comment != '[deleted]'] #Drop rows which include [deleted] in top comment
real = real[real.top_comment != '[removed]'] #Drop rows which include [removed] in top comment
real = real[real.top_comment != 'Welcome to r/TrueAskReddit. Remember that this subreddit is aimed at high quality discussion, so please elaborate on your answer as much as you can and avoid off-topic or jokey answers as per [subreddit rules](https://www.reddit.com/r/TrueAskReddit/about/sidebar).\n\n*I am a bot, and this action was performed automatically. Please [contact the moderators of this subreddit](/message/compose/?to=/r/TrueAskReddit) if you have any questions or concerns.*']
real['answers'] = real['answers'].str.replace('\n\n', ' ') #Delete line breaks from ChatGPT answers
real['top_comment'] = real['top_comment'].str.replace('\n', ' ') #Delete line breaks from Reddit comments
real = real[real.top_comment != f"A recent Reddit policy change threatens to kill many beloved third-party mobile apps, making a great many quality-of-life features not seen in the official mobile app **permanently inaccessible** to users. On May 31, 2023, Reddit announced they were raising the price to make calls to their API from being free to a level that will kill every third party app on Reddit, from [Apollo](https://www.reddit.com/r/apolloapp/comments/13ws4w3/had_a_call_with_reddit_to_discuss_pricing_bad/) to [Reddit is Fun](https://www.reddit.com/r/redditisfun/comments/13wxepd/rif_dev_here_reddits_api_changes_will_likely_kill/) to [Narwhal](https://www.reddit.com/r/getnarwhal/comments/13wv038/reddit_have_quoted_the_apollo_devs_a_ridiculous/jmdqtyt/) to [BaconReader](https://www.reddit.com/r/baconreader/comments/13wveb2/reddit_api_changes_and_baconreader/). Even if you're not a mobile user and don't use any of those apps, this is a step toward killing other ways of customizing Reddit, such as Reddit Enhancement Suite or the use of the old.reddit.com desktop interface . This isn't only a problem on the user level: many subreddit moderators depend on tools only available outside the official app to keep their communities on-topic and spam-free. ​ What can *you* do? 1. **Complain.** Message the mods of r/reddit.com, who are the admins of the site: message [/u/reddit](https://www.reddit.com/u/reddit/): submit a [support request](https://support.reddithelp.com/hc/en-us/requests/new): comment in relevant threads on [r/reddit](https://www.reddit.com/r/reddit/), such as [this one](https://www.reddit.com/r/reddit/comments/12qwagm/an_update_regarding_reddits_api/), leave a negative review on their official iOS or Android app- and sign your username in support to this post. 2. **Spread the word.** Rabble-rouse on related subreddits. Meme it up, make it spicy. Bitch about it to your cat. Suggest anyone you know who moderates a subreddit join us at our sister sub at [r/ModCoord](https://www.reddit.com/r/ModCoord/) \\- but please don't pester mods you *don't* know by simply spamming their modmail. 3. **Boycott** ***and*** **spread the word...to Reddit's competition!** Stay off Reddit as much as you can, instead, take to your favorite *non*\\-Reddit platform of choice and make some noise in support! https://discord.gg/cscareerhub https://programming.dev 4. **Don't be a jerk.** As upsetting this may be, threats, profanity and vandalism will be worse than useless in getting people on our side. Please make every effort to be as restrained, polite, reasonable and law-abiding as possible. *I am a bot, and this action was performed automatically. Please [contact the moderators of this subreddit](/message/compose/?to=/r/cscareerquestions) if you have any questions or concerns.*"]
real['top_comment'] = real['top_comment'].str.replace('# ', ' ') #Deleting all # with a space afterwards as represents headerAt this point, we can do a little EDA and see what words are being used the most. We will use the NLTK (Natural Language Toolkit) to help analyze our text, alongside CountVectorizer from the scikitlearn library.
The block of code below performs text preprocessing and vectorization on the answers collected from Reddit, using the ‘top_comment’ column of our dataframe named “real”. It starts by initializing a CountVectorizer object, configured to exclude English stopwords (stopwords are common words which are excluded from analysis as they don’t carry much semantic meaning). Then, it fits the CountVectorizer to the ‘top_comment’ column, learning the vocabulary of the text data. Next, it transforms the text data into a matrix representation, where each row represents a comment and each column represents a unique word in the vocabulary, with cell values indicating word counts. Finally, it converts the sparse matrix into a dataframe, creating a structured dataset suitable for further analysis or machine learning tasks. We will also plot the 30 most used words to see if we can notice anything of importance.
#Instantiate CVEC while excluding stop words
cvec = CountVectorizer(stop_words='english')
#Fit to column
cvec.fit(real['top_comment'])
#Transform column
top_comments = cvec.transform(real['top_comment'])
#Dataframe with transformed data
df_reddit_cvec = pd.DataFrame(top_comments.todense(), columns = cvec.get_feature_names_out())
df_reddit_cvec
#Set figure size
plt.figure(figsize=(15,7))
#Plotting 30 most used words
df_reddit_cvec.sum().sort_values(ascending=False).head(30).plot(kind='barh')
plt.title("Most Frequent Words from Reddit (Excluding Stop Words)")
plt.xlabel('Frequency')
plt.ylabel('Word')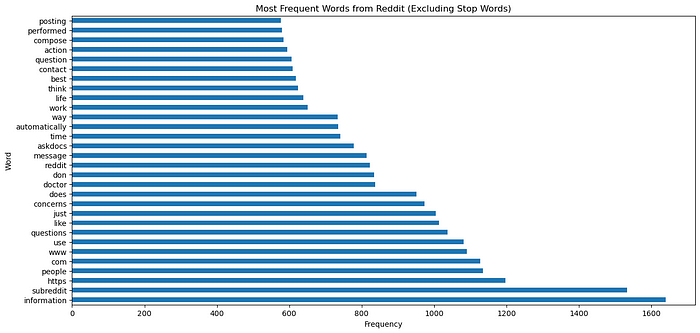
From the visual above, we can see there are certain words showing up which ChatGPT would never spit out such as www, com, askdocs, etc. Below we will create a loop to remove any rows which contain these keywords.
# Define a list of keywords to check for in 'top_comment' column
keywords_to_exclude = ['www', 'https', 'com', 'subreddit', 'reddit', 'askdocs', 'askculinary', 'askengineers', 'cscareerquestions', 'TrueAskReddit']
# Iterate through each keyword and remove rows containing it in 'top_comment'
for keyword in keywords_to_exclude:
real = real[~real['top_comment'].str.contains(keyword)]
# Reset index after removing rows
real.reset_index(drop=True, inplace=True)I did the same for our ChatGPT answers, all located in the ‘answers’ column within the dataframe named “real”. However, no further cleaning was needed so I will leave this step out of the article for redundancy.
The nature of this problem is a binary classification issue; either a response is given by a human, or by ChatGPT. Currently we have 3 columns in our dataframe consisting of our question, a human answer, and ChatGPT’s answer.
We will have to create a new dataframe, with all of the answers in one column, and the second column explicating who the answer is from. We will use 0 for human answers, and 1 for ChatGPT answers.
#New dataframe with answers from human, and 0 to represent human response
df1 = pd.DataFrame()
df1['answer'] = real['top_comment']
df1['who_from'] = 0
#New dataframe with answers from AI, and 1 to represent AI response
df2 = pd.DataFrame()
df2['answer'] = real['answers']
df2['who_from'] = 1
#Put df1 and df2 together
df = pd.concat([df1, df2])
df = df.reset_index()
df = df.dropna()Once complete, you should have something which looks like this:

Part 3: NLP (Natural Language Processing) & Classification Modelling.
When it comes to NLP & Classification models, there are a myriad of ways too which you can go about it. Since we are working with a binary classification problem, I’ve decided to focus on Log Regression and Bernoulli Naive Bayes (BNB) as our choice for modelling. I will talk over 3 different methods in this article, but you can find a total of 8 within the repo if you would like to see/explore more.
Baseline & Model Specifications
Firstly we will figure out the baseline for our model. Setting a baseline provides a point of reference for evaluating the performance of our machine learning models. Understanding the baseline performance helps in determining whether the developed models offer significant improvements over simple, naive approaches and guides the selection of appropriate algorithms and feature engineering strategies.
We will do this by first assigning the data into either predictive (X) variable, or target (Y) variable. The ‘answer’ column will be our predictive variable (what we use too make predictions) while the ‘who_from’ column will be our target (what we are trying to predict).
We’ll also have to split our data into training and testing sets, and get a baseline for our y_test set to compare to when we make our predictions.
#Split data into predictive variables and target variable
X = df['answer']
y = df['who_from']
#Baseline
y.value_counts(normalize = True)
#Train test split, test size 20%
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
#y_test baseline
y_test.value_counts(normalize = True)Our baseline for y is 50% Reddit responses and 50% ChatGPT responses. For our y_test, our baseline is 52.9% for Reddit, and 47.1% for ChatGPT.
For our models, we will be using either Logistic Regression or Bernoulli Naive Bayes, mixed in with either Count Vectorization or TFIDF Vectorization (Terms Frequency Inverse Document Frequency Vectorization). Here’s a short definition for each:
- Logistic Regression: A linear classification algorithm used to model the probability of a binary outcome based on one or more predictor variables.
- Bernoulli Naive Bayes: A variant of the Naive Bayes algorithm suitable for binary feature vectors, often used for text classification tasks.
- Count Vectorization: A method of converting text data into numerical vectors by counting the frequency of each word in a document, typically used for bag-of-words models.
- TFIDF Vectorization: A method of converting text data into numerical vectors by weighting the term frequency (TF) by the inverse document frequency (IDF), aiming to highlight words that are important to individual documents but not common across the entire corpus.
Model 1: Log Regression + TFIDF Vectorization
For our first model, we will implement a text classification task using the TFIDF (Term Frequency-Inverse Document Frequency) vectorization technique and a logistic regression model. First, we initialize a TFIDF vectorizer to convert the text data into numerical vectors. The training data is then transformed using this vectorizer, while the testing data is transformed using the same vectorizer to maintain consistency. Next, we instantiate a logistic regression model and fit it to the training data. After training, we predict the target variable for the testing data and evaluate the model’s performance using a confusion matrix, which provides insights into the model’s ability to correctly classify instances. Additionally, we calculate the accuracy scores of the model on both the training and testing data to assess its overall performance. Finally, we visualize the confusion matrix to gain a better understanding of the model’s strengths and weaknesses in classifying the data.
#Instantiate TFIDF vectorizer
tfidf = TfidfVectorizer()
#Fit and transforming training data
X_train_tfidf = tfidf.fit_transform(X_train)
#Transform testing data using same TFIDF Vectorizer
X_test_tfidf = tfidf.transform(X_test)
#Instantiate Log Regression model
lr = LogisticRegression()
#Fit Log Regression model to training data
lr.fit(X_train_tfidf, y_train)
#Predict target variable for testing data
y_pred = lr.predict(X_test_tfidf)
#Calculate confusion matrix using actual and predicted values
cm = confusion_matrix(y_test, y_pred)
#Create and display confusion matrix plot
disp = ConfusionMatrixDisplay(confusion_matrix = cm)
disp.plot()
#Calculate normalized value counts of predicted values (compare to baseline)
y_pred_norm = pd.Series(y_pred).value_counts(normalize = True)
#Calculate accuracy score on training data
train_score = lr.score(X_train_tfidf, y_train)
#Calculate accuracy score on testing data
test_score = lr.score(X_test_tfidf, y_test)
print(y_pred_norm, train_score, test_score)
The values which Model 1 gave in relation to the last 3 lines of code:
- y_pred human: 53.2%
- y_pred ChatGPT: 46.8%
- Train score: 95.0%
- Test score: 89.0%
Model 2: Bernouli Naive Bayes + Count Vectorization using Pipeline & GridSearch w/Stop Words
The second model starts by setting up a pipeline. A pipeline is a sequence of data processing steps that are chained together to automate workflow. In this pipeline, we use CountVectorizer to convert text data into numerical feature vectors and the Bernoulli Naive Bayes classifier for classification. We then define a set of parameters to be tuned using GridSearchCV, a technique that exhaustively searches through a specified parameter grid to find the best combination of hyperparameters. Through 5-fold cross-validation, the model is trained on various subsets of the training data to ensure robustness. Once the best model is identified, we make predictions on the test data and evaluate its performance.
#Set up pipeline
pipe = Pipeline([
('cvec', CountVectorizer()),
('bnb', BernoulliNB())
])
#Setting up (English) stop words
nltk_stop = stopwords.words('english')
#Pipeline parameters
pipe_params = {
'cvec__max_features' : [None, 1000], # Maximum number of features fit
'cvec__min_df' : [1, 5, 10], # Minimum number of documents needed to include token
'cvec__max_df' : [0.9, .95], # Maximum number of documents needed to include token
'cvec__ngram_range' : [(1, 2), (1,1)], #Check (individual tokens) and also check (individual tokens and 2-grams)
'cvec__stop_words' : ['english', None, nltk_stop] #Words to remove from text data
}
#Instantiate GridSearchCV.
gs = GridSearchCV(pipe, #Object we are optimizing
pipe_params, #Parameters values for which we are searching
cv = 5) #5-fold cross-validation
#Fit GridSearch to training data.
gs.fit(X_train, y_train)
#Get predictions
preds = gs.predict(X_test)
#View confusion matrix
disp = ConfusionMatrixDisplay.from_estimator(gs, X_test, y_test, cmap='Reds', values_format='d');
disp.plot()
#Calculate normalized value counts of predicted values (compare to baseline)
y_pred_norm = pd.Series(preds).value_counts(normalize = True)
#Calculate parameters which result in highest score
best_param = gs.best_params_
#Calculate highest mean score
best_score = gs.best_score_
#Calculate score on training data
train_score = gs.score(X_train, y_train)
#Calculate score on testing data
test_score = gs.score(X_test, y_test)
print(y_pred_norm, best_param, best_score, train_score, test_score)
The values Model 2 gave:
- y_pred Human: 61.1%
- y_pred ChatGPT: 38.9%
- Best score: 87.5%
- Train score: 90.8%
- Test score: 87.8%
Model 3: Log Regression + Count Vectorization using Pipeline & GridSearch w/Lemmatization
Our final model implements a pipeline for text classification using logistic regression with hyperparameter tuning through grid search. Initially, the text data undergoes lemmatization, a process that reduces words to their base or dictionary form (lemma). This helps in standardizing word with different forms to their common base form. Then, the data is split into training and testing sets. The pipeline is set up with two main components: CountVectorizer for converting text data into numerical vectors and Logistic Regression for classification. Various parameters for CountVectorizer, such as the maximum number of features, minimum document frequency, and n-gram range, are specified for optimization. GridSearchCV is employed to systematically search through these parameter combinations using 5-fold cross-validation. After fitting the pipeline to the training data, predictions are made on the testing data and the resulting performance metrics are calculated.
#Initalize Whitespace tokenizer
w_tokenizer = nltk.tokenize.WhitespaceTokenizer()
#Initalize WorkNet lemmatizer
lemmatizer = nltk.stem.WordNetLemmatizer()
#Define function to lemmatize text
def lemmatize_text(text):
return ' '.join([lemmatizer.lemmatize(w) for w in w_tokenizer.tokenize(text)])
#Apply lemmatization to predictive variables
X = df['answer'].apply(lemmatize_text)
#Train test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
#Set up pipeline
pipe = Pipeline([
('cvec', CountVectorizer()), # Vectorization
('lr', LogisticRegression(max_iter=1000)) #Raised max_iter as was getting an error that total no. of iterations reached limit
])
#Pipeline parameters
pipe_params = {
'cvec__max_features': [None, 500, 1000, 5000],
'cvec__min_df': [1, 10, 50],
'cvec__max_df': [0.25, .5, 0.95],
'cvec__ngram_range': [(1, 2), (1, 1)],
'cvec__stop_words': ['english', None]
}
#Instantiate GridSearchCV
gs = GridSearchCV(pipe, #Object we are optimizing
pipe_params, #Parameters values for which we are searching
cv = 5) #5-fold cross-validation.
#Fit GridSearch to training data
gs.fit(X_train, y_train)
#Get predictions
preds = gs.predict(X_test)
#View confusion matrix
disp = ConfusionMatrixDisplay.from_estimator(gs, X_test, y_test, cmap='Reds', values_format='d');
disp.plot()
#Calculate normalized value counts of predicted values (compare to baseline)
y_pred_norm = pd.Series(preds).value_counts(normalize = True)
#Calculate parameters which result in highest score
best_param = gs.best_params_
#Calculate highest mean score
best_score = gs.best_score_
#Calculate score on training data
train_score = gs.score(X_train, y_train)
#Calculate score on testing data
test_score = gs.score(X_test, y_test)
print(y_pred_norm, best_param, best_score, train_score, test_score)
The values Model 3 gave:
- y_pred Human: 55.3%
- y_pred ChatGPT: 44.7%
- Best score: 91.1%
- Train score: 99.2%
- Test score: 90.5%
Conclusion
The analysis of the classification models revealed that out of the three models evaluated, the final one emerged as the most effective in distinguishing between human-generated responses and those generated by ChatGPT. With a prediction accuracy of 90.5% on the testing data, the model demonstrated robust performance in correctly categorizing responses. Notably, the best score achieved during hyperparameter tuning reached 91.1%, underscoring the effectiveness of the chosen techniques in optimizing model performance. Furthermore, the model exhibited high consistency between training and testing scores, with minimal overfitting, as evidenced by the marginal difference between the two. These findings underscore the significance of employing natural language processing techniques coupled with classification modeling in discerning between human and bot-generated responses, offering valuable insights for maintaining the integrity of online conversations and enhancing the development of AI-driven content moderation tools.
